When teams ship their first AI agent, they usually find out — within a few weeks — that the model wasn’t the problem. The agent hallucinates a customer ID three turns into a conversation and then cheerfully references it for the rest of the session. A 50-step task dies at step 42 because the context window is filled with tool output nobody needed. A “simple” migration tool that worked beautifully on 10 files collapses on 100 because the noise drowns out the signal. The team retries with a bigger model. The bugs move, but they don’t leave.
This is the pattern that has pushed an entire sub-discipline — context engineering — from niche jargon to what Cognition has called “effectively the #1 job of engineers building AI agents.” In April 2026, Thoughtworks moved context engineering into the Adopt ring of its Technology Radar, framing it as having “evolved from an optimization tactic into a foundational architectural concern for modern AI systems.” In their words, the context window is “a design surface,” and your job is to “intentionally construct the AI’s information environment.”
In the last six months, every serious agent builder has published essentially the same lesson: what separates a demo from a production agent is not which model you pick, but how you shape the information that model sees on every turn.
For engineering leaders, this matters beyond the mechanics. Context engineering is reshaping how we structure codebases, document systems, think about memory and observability, and which skills we value on our teams. This post is a tour of that landscape.
Part 1: What context engineering actually is
Prompt engineering asked: “What’s the best way to phrase the instruction?” Context engineering asks a bigger question: “What is the complete configuration of tokens — system prompt, tools, examples, retrieved documents, message history, memory, tool outputs — most likely to produce the behavior we want?”
Anthropic’s framing is useful here. Its Applied AI team describes context engineering as “the natural progression of prompt engineering”—a shift required because agents now operate over many turns and long horizons, so the entire evolving state of the context window must be managed. Clara Chong, writing in Towards Data Science, puts it more bluntly: “performance is far less about how much context you give a model, and far more about how precisely you shape it.”
Or, as Thoughtworks puts it, context engineering is curating what the model sees to get better results.
The reason this distinction matters is that prompts are a discrete artifact — you write one, you ship it. Context, in an agent loop, is built fresh on every inference call. Every tool result, every retrieved document, every piece of memory, every turn of conversation — all of that is part of the context being assembled, continuously, by your system. The “prompt” is one layer of a stack that the engineering team owns end-to-end.
Andrej Karpathy’s mental model has stuck because it’s accurate: the LLM is a CPU, the context window is its RAM, and your job as an engineer is to decide what deserves a spot in that RAM at each step. An operating system doesn’t load every file into memory; it loads what’s needed right now. Agents need the same discipline.
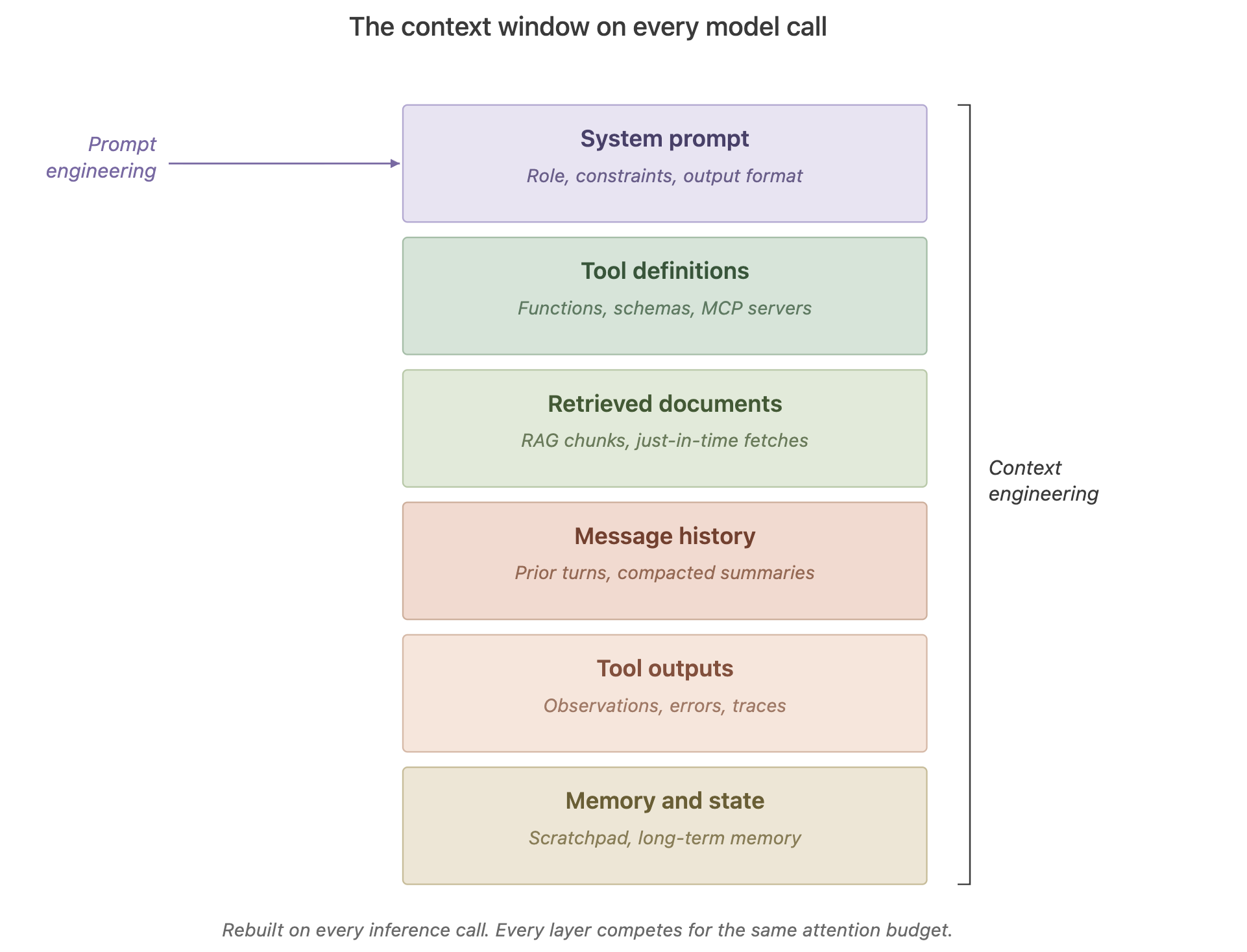
Part 2: Why bigger context windows did not solve the problem
A fair question to ask in 2026, when frontier models ship with one- and two-million-token context windows, is whether any of this still matters. If you can fit a small library into the prompt, does it matter what you leave out? The counterintuitive answer is that larger context windows made context engineering more, not less, important.
Several forces conspire against naive “just give it everything” approaches:
Context rot. Chroma Research’s widely cited study and a follow-up from Databricks Mosaic found that model accuracy degrades non-uniformly and begins to drop well before the advertised context limit. The Manus team now advises picking a “pre-rot threshold” well below the hard limit — typically 128K–200K tokens for models with 1M-token windows — and compacting before you hit it. The degradation isn’t a cliff; it’s a slope that starts much earlier than the marketing suggests.
Lost-in-the-middle. Research dating back to Liu et al. in 2023 has shown that transformers reliably recall information at the beginning and end of a long context, while information buried in the middle is statistically disadvantaged. An agent with 150k tokens of accumulated tool output may be effectively ignoring the middle 100k of it. The token count in your prompt logs tells you nothing about what the model actually saw.
Attention is a finite budget. Transformer attention is quadratic — every token attends to every other token. As Anthropic puts it, the model has a finite “attention budget” that gets depleted by every token introduced. Models also train on sequences shorter than their inference-time limits, so they have fewer specialized parameters for very long-range dependencies.
Cost and latency. Even with caching, long contexts are expensive and slow. Manus reports an average input-to-output token ratio of roughly 100:1 in their production agent — meaning the overwhelming majority of what you pay for is context you’re sending, not content you’re getting back. Cached input tokens on Claude Sonnet run roughly 10x cheaper than uncached ones, which is why KV-cache hit rate has become, in Manus’s framing, “the single most important metric for a production-stage AI agent.”
Put together, these forces mean the effective context window you can actually use well is a fraction of the one you’re paying for. Context engineering is the discipline of staying inside that effective window while still giving the agent everything it needs.
Part 3: The four ways context fails in production
Drew Breunig’s taxonomy, widely adopted over the last year, names four patterns every agent team eventually runs into:
Context poisoning occurs when a hallucination or error enters the context and is repeatedly referenced, compounding over time. DeepMind’s Pokémon-playing Gemini agent became the example: once the agent’s “goals” section was corrupted with hallucinated objectives, it spent dozens of turns pursuing impossible items from a different game entirely. Because the corrupted state lives in the part of the context the agent consults on every decision, the false information keeps reinforcing itself.
Context distraction occurs when the context becomes so long that the model over-relies on recent history and under-relies on its trained knowledge. Google’s Gemini 2.5 technical report documents this past the 100k-token mark: agents begin “favoring repeating actions from its vast history rather than synthesizing novel plans.”
Context confusion occurs when the agent can’t cleanly distinguish between instructions, data, and structural markers, or when it’s given ambiguous tool definitions. A common cause is tool-set bloat: plug 10’s or 100s of MCP tools into an agent, and several could plausibly handle the same request, and the agent makes worse decisions than it would with a curated set of twelve.
Context clash occurs when two parts of the context flatly contradict each other — the system prompt says one thing, the retrieved documentation says another, and a prior turn establishes a third. Without explicit resolution logic, the model picks arbitrarily, and the output looks confident regardless.
All four compound quietly. By the time they show up in user-visible bugs, they’ve usually been degrading quality for a while. This is why observability — tracking what actually ends up in the context window, not just what you intended to put there — is becoming table stakes.

[Drew Breunig’s taxonomy of context failure modes. Each has its own mechanism and its own fix.]
Part 4: The core techniques
The field has converged on a handful of patterns, sometimes grouped as write, select, compress, and isolate (LangChain’s framing) or offload, retrieve, reduce, and isolate (the Manus / Clara Chong framing). We’ll use LangChain’s vocabulary as the canonical one.
Keep the system prompt at the right altitude
Anthropic uses a nice metaphor: prompts have an “altitude.” Too low, and you’ve hardcoded if-else logic that becomes brittle maintenance debt. Too high, and you’ve given the model vague guidance that assumes shared context that doesn’t exist.
The practical advice is counterintuitive for most teams: start with fewer instructions than you think you need, add only in response to observed failures. HumanLayer’s analysis of the Claude Code harness (citing IFScale) estimates that frontier thinking models can reliably follow ~150–200 instructions before performance degrades. That budget sounds large until you realize the harness itself consumes fifty instructions before you add anything. Every rule you put into CLAUDE.md or AGENTS.md competes with every other rule for that budget. More rules are rarely the right answer.
Thoughtworks flags this anti-pattern on its Radar as “agent instruction bloat” in the Caution ring. Their guidance: be deliberate and selective, add instructions only as needed, and continuously refine toward a minimal, coherent set.
Design tools like you’d design APIs
Tools are the contract between the agent and its world, and a bloated, overlapping tool set is one of the most common causes of failure. Anthropic’s heuristic: if a human engineer can’t definitively tell you which tool to use in a given situation, the agent can’t either. Tools should be self-contained, have minimal functional overlap, return token-efficient outputs, and be named in ways that make their use obvious (Manus uses consistent prefixes like browser_ and shell_).
A related Manus discovery worth internalizing: don’t dynamically add and remove tools mid-session. Tool definitions typically live near the front of the context, so modifying them invalidates the KV-cache for everything that follows — and worse, when older turns reference tools that no longer exist, the model gets confused or hallucinates.
Retrieve just-in-time, not up-front
Early agent architectures leaned heavily on pre-inference retrieval: embed everything, search, dump the top-k chunks into context. The field is shifting toward just-in-time retrieval — where the agent holds lightweight identifiers (file paths, IDs, URLs, stored queries) and pulls data into context only when it is needed.
Thoughtworks has given this pattern a formal name: progressive context disclosure. Instead of front-loading every reference an agent might need, these systems start with a lightweight index. The agent determines what’s relevant and pulls in only what’s needed, keeping signal-to-noise sharp at every step.
Claude Code is the canonical example. Instead of indexing the whole codebase into embeddings and praying the chunking strategy works, it uses glob and grep to navigate a real filesystem, reading files only when relevant. Metadata becomes a signal: a file named test_utils.py in a tests/ folder tells the agent something different than the same filename in src/core_logic/. Folder hierarchies, naming conventions, and timestamps all provide implicit context that the agent can reason over without any explicit loading.
This is why the “AI-friendly codebase” has become a design goal. Consistent naming, clear folder structure, self-descriptive file names, and good docstrings aren’t just nice-to-haves for human readers anymore; they now also determine how well your agents can navigate the code.
Offload to the filesystem
Related but distinct: treat the filesystem (or any external store) as an extension of the context window. Manus calls it “the ultimate context” — unlimited size, persistent, and directly operable by the agent. The model writes to files and reads from files on demand. Web pages can be dropped from context as long as the URL is preserved. Large tool outputs get written to disk with only the file path retained.
The key principle Manus emphasizes is reversibility: any compression strategy should be restorable. If the agent needs the data back, it should be able to recover it with a tool call. Aggressive one-way compression feels clean but destroys information whose importance only becomes obvious later.
Compact, don’t just truncate
The default reaction to a full context window is often to delete the oldest messages, a blunt tactic that risks purging the very instructions or goals that define the agent’s mission. This works right up until you delete the message where the user stated the actual goal. Compaction, which uses an LLM to summarize the existing context while preserving architectural decisions, unresolved issues, and critical details, is more robust.
Claude Code’s compaction preserves the five most recently accessed files, along with the summary. Manus keeps the most recent tool calls in raw, full-detail form so the model doesn’t lose its “rhythm” and output formatting. A lighter-touch variant: tool result clearing. If a tool was called forty turns ago and its output has been absorbed into subsequent reasoning, the raw result doesn’t need to keep consuming tokens. This is now a native feature on the Claude Developer Platform.
Manipulate attention through recitation
This one is almost too simple to take seriously until you watch it work. Manus noticed their agent, when given a complex multi-step task, spontaneously started creating a todo.md file and rewriting it after each step — checking off completed items and restating what was left. They kept the behavior because it solves a real problem: by constantly rewriting the plan to the end of the context, the agent pushes its global objective into the model’s most attended-to region. This directly counteracts lost-in-the-middle drift on long tasks.
The generalizable lesson: recency is attention currency. What you want the model to focus on should be near the end of the context, not buried ten tool calls back.
Keep the wrong stuff in
Another counterintuitive pattern from Manus: when the agent makes a mistake and gets an error, leave the error in the context. The impulse to clean up failed attempts is understandable but counterproductive. When the model sees its own failed action and the resulting stack trace, it updates its implicit beliefs and is less likely to repeat the mistake. Erasing failure removes evidence, and agents that can’t see their errors can’t learn from them within a session.
This generalizes into something important: error recovery is one of the clearest indicators of genuinely agentic behavior, yet most benchmarks test task completion under ideal conditions. A team that only optimizes for the happy path will build a brittle system.
Part 5: Context files, AGENTS.md, and the tools question
For coding agents specifically, a small but consequential standardization is happening around context files. Claude Code reads CLAUDE.md. Codex reads AGENTS.md. Cursor has .cursorrules. Copilot uses .github/copilot-instructions.md. Gemini CLI checks for GEMINI.md. These are all markdown files auto-loaded at session start, telling the agent things it would otherwise have to rediscover every session: “we use pnpm not npm,” “the test command is make test-integration.”
An October 2025 arXiv study of 466 open-source projects found AGENTS.md emerging as the likely cross-tool standard, with Linux Foundation backing and support across most major coding agents. Current best practice for teams maintaining multiple files: pick AGENTS.md as source of truth and symlink the others.
Thoughtworks has pushed this further, in a way worth considering at the org level. They list curated shared instructions for software teams in the Adopt ring — treating AI guidance as a collaborative engineering asset rather than a personal workflow. The specific recommendation: anchor instruction files into service templates, so every new repository scaffolded from the template inherits the latest agent workflows and rules by default.
The related pattern — skills as executable onboarding documentation — is worth a beat of its own. A /_setup skill can combine scripting with LLM-executed semantics for steps that can’t be scripted. Library and API creators can provide skills as part of their documentation. Platform teams can ship skills to lower the barrier to adoption for internal tools. Documentation stops being a static artifact and becomes an executable one, which means staleness becomes visible the moment it breaks.
The more interesting lesson from production use, though, is what not to put in context files:
- Don’t auto-generate them. An ETH Zurich study found LLM-generated
AGENTS.mdfiles reduced task success by 0.5–2% while increasing inference costs by more than 20%. Human-curated files produced a roughly 4-percentage-point improvement. The/initcommand that ships with most coding agents produces a starter that’s worse than having no file at all. - Don’t include things a linter handles. Telling an LLM to do a formatter’s job is expensive, slow, and non-deterministic. Use a hook to run the formatter and feed errors back to the agent.
- Don’t include architectural overviews. The same ETH study found that “Architecture” sections didn’t meaningfully improve behavior — they just increased token costs and encouraged unnecessary, broader file traversal.
- Don’t use long context files; keep them short. Target under 300 lines. Every line competes for attention with the task at hand.
A word on MCP
Worth flagging a counter-current, because it matters for integration decisions. As the Model Context Protocol has gained traction, many teams reach for it as the default integration layer. Thoughtworks puts this on their Caution list as “MCP by default.” Their argument, drawing on Justin Poehnelt: every protocol layer between an agent and an API introduces an “abstraction tax” — fidelity loss that compounds for complex APIs. In many cases, a well-designed CLI with good --help output and structured JSON responses gives agents everything they need without the protocol overhead. As Simon Willison has put it: “almost everything I might achieve with an MCP can be handled by a CLI tool instead.”
This isn’t a rejection of MCP — it’s legitimately valuable for structured tool contracts, OAuth boundaries, and governed multi-tenant access. But before adopting MCP for a given integration, it’s worth asking whether you actually need protocol-level interoperability, or whether a CLI plus a skill would serve the agent just as well at a fraction of the complexity.
The broader point for engineering leaders: context files, skills, and integration choices are all institutional knowledge made machine-readable. Teams with well-curated context artifacts effectively encode their tribal knowledge, enabling new humans and agents to ramp up faster.
Part 6: Multi-agent architectures — where it gets genuinely complex
Single-agent context engineering is hard. Multi-agent systems multiply every surface on which it can go wrong, and this is where the field is actively figuring things out.
The core appeal of multi-agent designs is context isolation. Instead of one agent trying to hold the entire task in its head, you have specialized sub-agents each working with a clean context on a focused sub-problem, returning compressed summaries to an orchestrator. Anthropic’s canonical subagent pattern, described in their research agent post, has sub-agents using tens of thousands of tokens during exploration but returning only 1,000–2,000 tokens of distilled conclusions to the parent. The main agent stays focused on synthesis; the mess of exploration stays walled off.
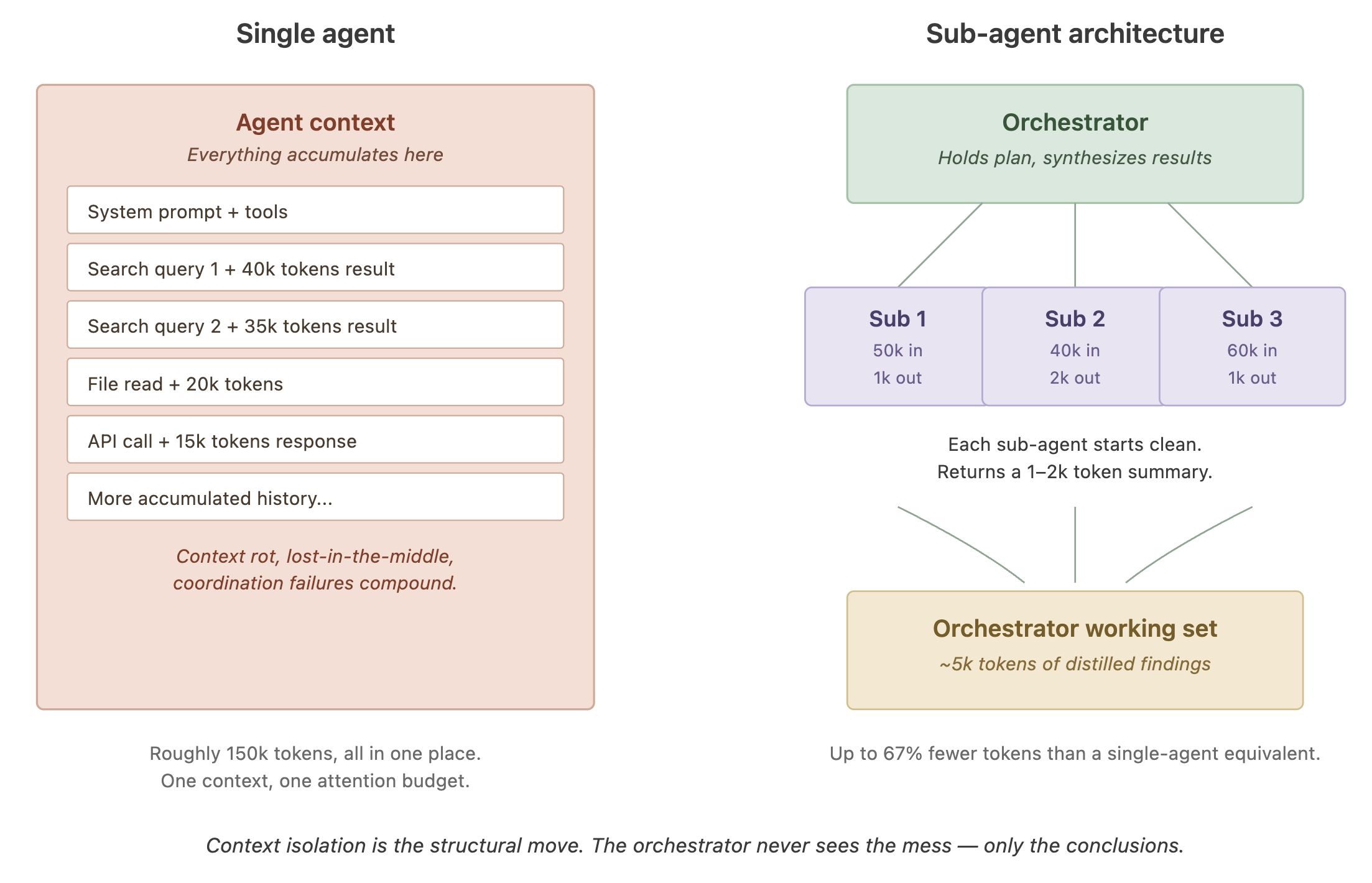
[Single-agent vs. sub-agent architecture. The orchestrator stays clean; sub-agents absorb the token cost of exploration.]
LangChain’s architecture guide reports that subagent architectures with proper context isolation processed 67% fewer tokens than a Skills-pattern alternative in one comparison. Anthropic has reported roughly 90% improvements in quality on complex research tasks using multi-agent patterns — but at roughly 15x the token cost of a single-agent baseline. The tradeoff is real and needs to be sized against the task.
The failure modes at this layer are worse than the single-agent versions:
Context explosion. Google’s ADK team describes this vividly: if a root agent passes its full history to a sub-agent, and that sub-agent does the same, the token count compounds exponentially. Their fix: every agent-to-agent handoff is scoped explicitly, with the callee seeing only the specific input it needs, not the parent’s entire history.
Collusive validation. This is a failure mode where one agent’s errors are “rubber-stamped” or reinforced by another agent because they share the same underlying logic, training data, or biases. When an implementation agent and a review agent share a training distribution, the reviewer tends to approve exactly the kinds of errors the implementer produces. Using genuinely different models (or at least different prompts and tool sets) for implementation and review helps. To prevent this, engineering teams use Diversity Engineering to ensure the “checks and balances” actually work. Use strategies such as model diversity, negative prompting, tool-based validation, and role isolation.
Cross-tenant context leakage. In commercial multi-tenant systems, if your canonical storage is tenant-partitioned but your retrieval index is globally indexed with soft filters (searching all data and then filtering the results by Tenant ID afterward), isolation is advisory rather than enforced. Cursor’s use of Merkle-tree-based content proofs is one production pattern — results are returned only if the requester can prove legitimate possession. Thoughtworks promotes a related pattern as role-based contextual isolation in RAG: move access control from the application layer down to the retrieval layer, tagging every data chunk with role-based permissions at indexing time so the model literally cannot access unauthorized context.
The coordination overhead trap. This is the one most teams underestimate. Google Research found that multi-agent coordination reduced performance by 39–70% on sequential reasoning tasks compared to single-agent approaches. Coordination has a cost, and for tasks that are really sequential in nature — where each step genuinely depends on the previous one — the coordination overhead produces worse outcomes, not just slower ones. A common anti-pattern: splitting a task into specialist agents when what you actually had was a single-agent prompt-engineering problem in disguise.
The practical heuristic emerging is to start with a single agent and move to multi-agent only when you have genuinely parallelizable work, or when your task needs enforced specialization, or when a single context window is legitimately not big enough. Don’t pay the coordination tax for a problem you could have solved with better context engineering within a single agent.
Durability — the quiet operational concern
One more thing Thoughtworks put on their Caution list: ignoring durability in agent workflows. LLM calls and tool calls fail. For short-lived tasks this is survivable, but for workflows that run for days or weeks — large codebase migrations, deep research — durability is not optional. LangGraph and Pydantic AI now offer stateful persistence; standalone platforms like Temporal, Restate, and Golem are adding agent support. For anything running longer than a few minutes, the question isn’t whether to plan for durability — it’s which layer to build it into.
Part 7: Memory, evolving context, and the frontier
Two threads worth watching. The first is structured, long-term agent memory. Anthropic shipped a file-based memory tool in beta with Sonnet 4.5 last fall, allowing agents to retain knowledge across sessions. The Claude Playing Pokémon demo is oddly instructive here: the agent maintains explicit step counts, training progress, maps of explored regions, and combat notes in files it reads after context resets, enabling coherent multi-hour strategies. Weaviate and Neo4j are both pushing a more structured variant in which memory lives in a knowledge graph—a “context pyramid” with a stable base (system prompts, canonical facts), a dynamic middle layer (recent examples, retrieved memories), and a volatile top (current data).
The failure mode teams discover quickly: memory without revision becomes a landfill. If you persist everything the agent decides is worth remembering, long-term memory becomes another place for context pollution to accumulate — except now it’s harder to see and gets replayed into every session. Conflict resolution, deletion, and demotion need to be first-class operations, not afterthoughts. Clara Chong’s rule of thumb: only promote to durable memory things that will continue to constrain future reasoning — persistent preferences, architectural decisions, hard constraints.
One related pattern Thoughtworks has pulled out — in the Assess ring — is the context graph. Decisions, policies, exceptions, precedents, evidence, and outcomes are modeled as first-class connected nodes. Where systems of record capture what happened, a context graph captures why, turning institutional reasoning that typically lives in Slack threads and people’s heads into a queryable, machine-readable structure. An agent handling a discount exception, for example, can traverse decision traces to determine whether the exception reflects standing policy or a one-time override, a distinction a flat document store loses.
The second thread is evolving context itself. The ACE (Agentic Context Engineering) paper from Stanford and collaborators, updated through March 2026, treats contexts as evolving playbooks — they accumulate, refine, and reorganize strategies through cycles of generation, reflection, and curation. The framework reports improvements in agent benchmarks, essentially by letting the system prompt itself to improve over time without model weight updates.
Thoughtworks has a closely related practice in their Assess ring called the feedback flywheel: capture successes and failures during an agent session and use them to improve the predictability of future sessions. Over time, this compounds — curated shared instructions get sharper, feedback sensors catch more regressions, and the harness becomes a durable team asset.
Part 8: Dissenting views
The narrative above represents a strong emerging consensus, but consensus isn’t the same as correctness. It’s worth engaging with the picture where it’s less settled than a reading of the primary sources would suggest.
Is context rot as severe as Chroma’s framing implies? Chroma is a vector database company, and its product gets more attractive the more teams conclude that “just stuff everything in the context window” is a losing strategy. That’s not a reason to dismiss their findings — the methodology is solid and has been at least partially replicated — but it’s a reason to read the framing carefully. Some practitioners argue the effect sizes in controlled needle-in-haystack tests overstate real-world degradation, where prompts are richer, and the model’s parametric knowledge often compensates.
The Google/MIT multi-agent study has legitimate caveats. The 39–70% degradation figure for sequential tasks has been widely cited, but critics have pointed out that the study used a fixed token budget of 4,800 tokens per configuration — well below what real deployments typically use. Coordination overhead may look different at 50,000-token budgets. Four benchmarks, while more than most studies, don’t capture every production scenario. The directional finding — that multi-agent systems aren’t universally better — holds up, but the specific numbers shouldn’t be treated as laws.
MCP-skepticism may have already peaked. The “MCP by default” caution resonated because early MCP integrations were heavy and expensive. But Anthropic has since shipped the MCP Tool Search for Claude Code, and Simon Willison noted about that launch: “context pollution is why I rarely used MCP — now that it’s solved, there’s no reason not to hook up dozens or even hundreds of MCPs.” The CLI-as-alternative argument remains sound for many cases, but the balance may be shifting faster than the Radar suggests.
The ETH Zurich AGENTS.md finding has been contested. A concurrent January 2026 study measuring the same question found AGENTS.md reduced median runtime by 28% and output token consumption by 16% while maintaining task completion. The two studies used different benchmarks and measured different things, but teams taking “don’t write AGENTS.md files” as a conclusion from the first study are oversimplifying. The truer reading is that context files help when they’re specific, behavioral, and short, and hurt when they’re autogenerated architectural overviews.
Context engineering as a discipline is not universally endorsed. Some researchers argue the whole framing is a transitional concern — that as models get better at managing their own attention and as inference-time techniques like learned routing mature, the need for elaborate context curation will shrink. The case for investing heavily in context-engineering infrastructure depends partly on a belief that the problem won’t be absorbed into the models themselves. While we can agree to disagree, this argument will either strengthen or weaken as LLMs get smarter and token usage becomes cheaper. Time will tell. But regardless of this, there is still IMO no reason to stuff everything into the context,
None of this invalidates the core lessons in this post.
What this means for engineering leaders
If you’re running an engineering org adopting agents, the shift from “choose the best model” to “engineer the best context” has real operational implications:
Context engineering is a skill worth hiring for explicitly. It lives somewhere between systems engineering, information architecture, and developer tooling. The best practitioners seem to come from a few different backgrounds: infrastructure engineers who think in terms of resources and budgets, technical writers who think about how information is structured for readers, and product-minded developers who relentlessly observe how the agent actually behaves. Watch for people who ask “what does the model see?” before they ask “which model should we use?”
Observability for agents is observability for context. The same way you wouldn’t debug a distributed system without tracing, you can’t debug an agent without being able to see the exact context on every model call. The tools for this exist now – LangSmith, Langfuse, Arize, and Braintrust. Investing in it early pays for itself the first time you hunt down a hallucination that turned out to be a three-day-old tool result still lurking in history.
Treat shared instructions as team infrastructure. This is the Thoughtworks “curated shared instructions” point, and it’s worth internalizing as a leadership move. Instead of every developer writing their own prompts and maintaining their own rules files, anchor AGENTS.md into your service templates. Build a small library of skills for your internal platforms. Run a periodic “feedback flywheel” retrospective on your agent harness — what patterns cost the team time this sprint, and what rule or skill would have prevented it? These practices convert AI adoption from an individual productivity hack into a compounding team asset.
Documentation practices start mattering differently. An “AI-friendly” codebase — consistent naming, clean folder structure, good docstrings, a tight AGENTS.md file — is measurably better for agent-assisted development. This is a rare case where an investment that helps humans also directly accelerates automation. If you were looking for an excuse to do the documentation cleanup everyone has been avoiding, context engineering is it.
Cost discipline is context discipline. When 90% of your agent’s token spend is input (not output), and every token is either cached or not, the economics of your agents are effectively determined by how stable your context prefixes are and how aggressively you’re compacting. Teams without per-agent token attribution will discover runaway costs only after they’re expensive.
Plan for durability before you need it. For anything beyond prototypes — especially workflows that run longer than a few minutes or involve humans in the loop — durable execution isn’t optional. Pick a framework that supports it natively, or plan the infrastructure layer that will.
Expect the techniques to keep moving. Manus’s phrase for this work — “Stochastic Graduate Descent” — is uncomfortably accurate. The architecture you build today will likely need significant revisions within a year. Don’t over-invest in any single technique; invest in the evaluation infrastructure that tells you whether your changes are helping.
Closing out…
The most striking thing about the last year of writing on context engineering — from Anthropic, from Manus, from Google, from the Thoughtworks Radar, from independent engineers building real systems — is how consistent the lessons are. Different frameworks, different products, different scales, but the same principles keep surfacing: treat context as finite, prefer curation over accumulation, compact reversibly, isolate where you can, and watch what the model actually sees.
We are still early. The techniques will keep evolving, the tooling will keep improving, and teams that treat context as a first-class system — with its own architecture, lifecycle, budgets, and tests — will keep quietly out-shipping teams that treat it as a string someone is concatenating. For engineering leaders, that’s the shift worth internalizing.